
Classifier instances define the logic that the ASDD profiler uses to identify sensitive information. For an overview of classifiers and related concepts, refer to Discovering Your Sensitive Data. Each classifier instance is based on a classifier framework that implements the recognition logic.
An overview of the available frameworks is available in the classifier concept section. The Classifier Management section of this article describes how to use the API Client to retrieve a detailed description of all classifier frameworks on the system, along with their configurations schemas.
To view a list of all classifier instances available, click Classifiers under the Settings tab:
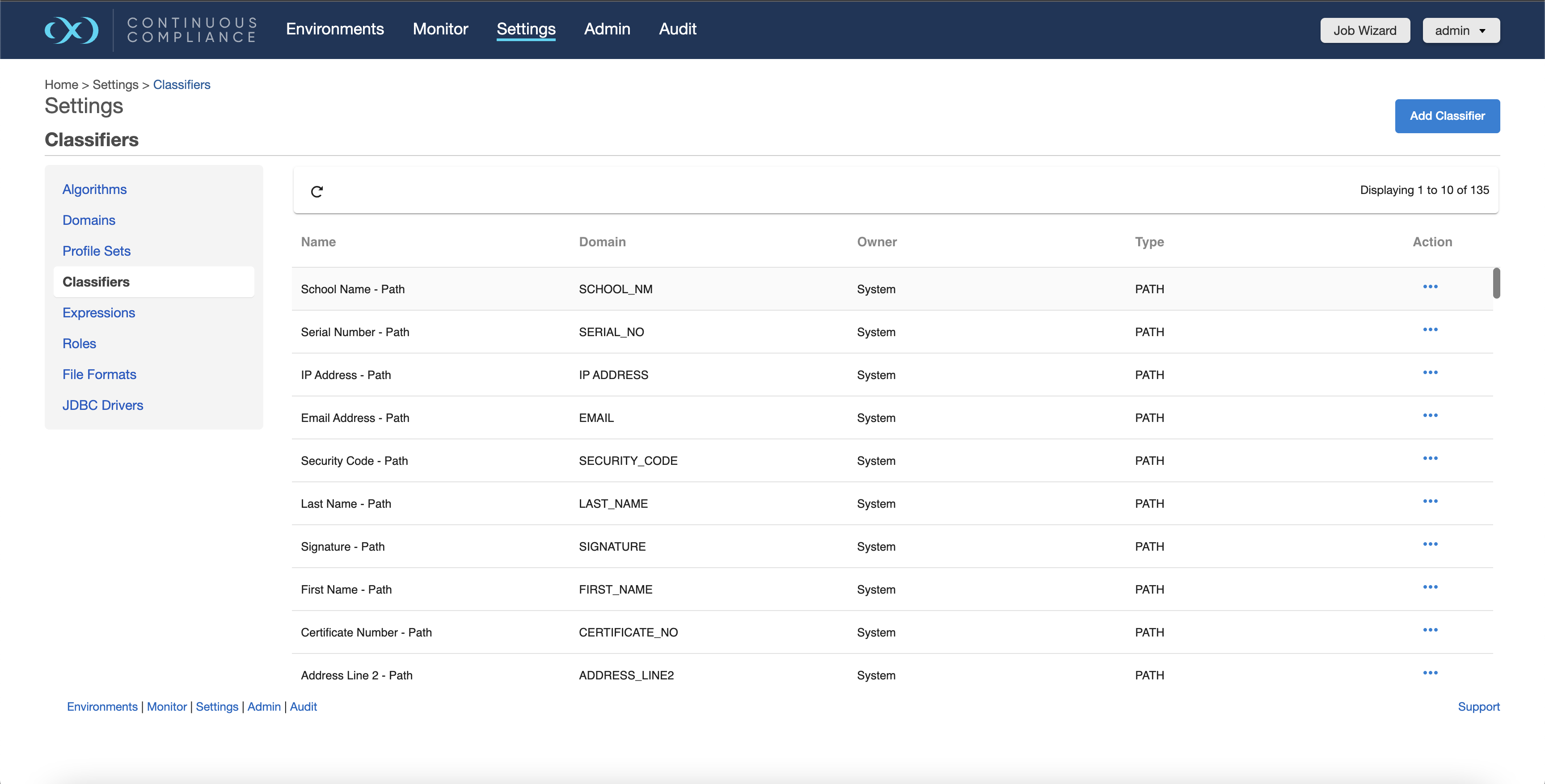
This UI screen does not currently support creation or modification of classifiers.
Managing classifiers using the API client
In order to manage classifiers using the API client, you should have some familiarity with REST APIs and JSON data encoding. Access the API Client, as described in the Masking API Client section, and authenticate by pressing the Authorize button at the upper right part of the screen. Locate the API paths related to classifiers:
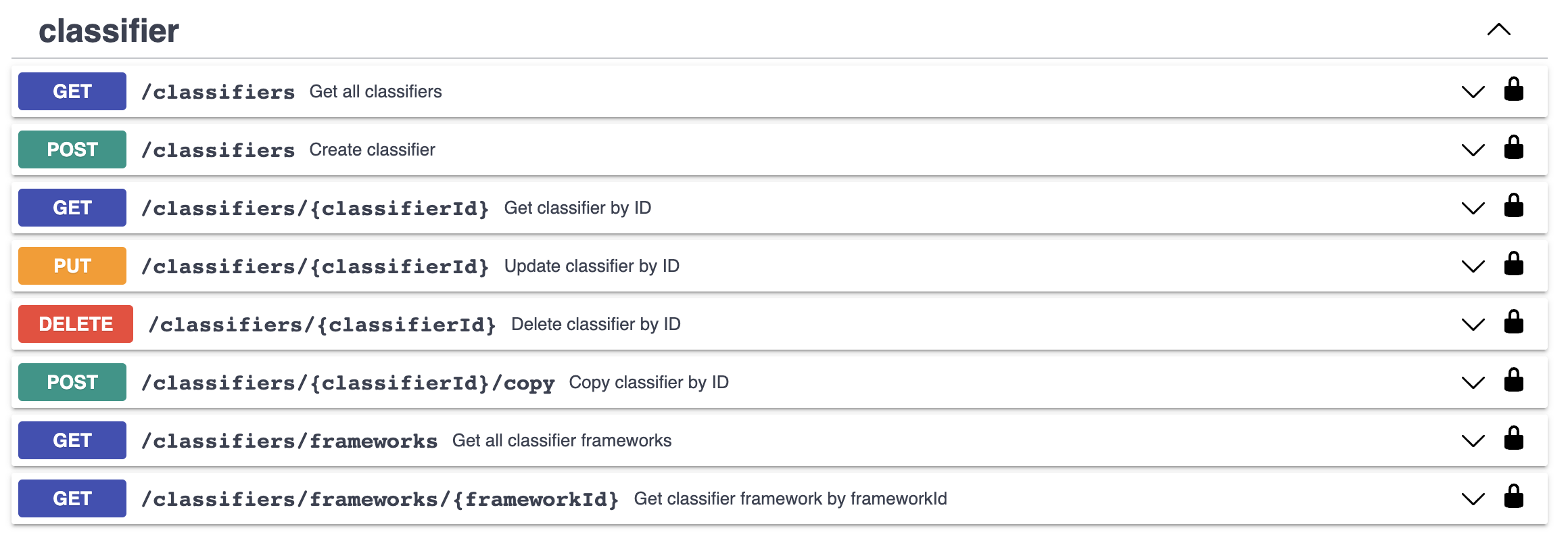
Each of these API path's purpose is as expected based on the operation; GET to view the configuration of existing classifiers, PUT to modify the configuration of an existing classifier, POST to create a new classifier, and DELETE to delete a classifier.
Note
The built-in classifier instances delivered with the system are read-only and cannot be modified or deleted.
The classifiers/frameworks paths allow retrieval information about the available classifier frameworks. In particular, making a request to these endpoints with include_schema=true will return open API style descriptions of the schema for the classifier frameworks. It is also necessary to use this API to map classifier framework type names, such as 'PATH' or 'REGEX', to numeric the frameworkId when creating classifier instances.
When creating a new classifier, it can be helpful to first perform a GET operation that retrieves the configuration of an existing classifier instance, using the intended framework as a starting point.
Example: Creating a new PATH classifier
In this example, a database contains some columns named snack_pref1, snack_pref2, etc. The columns contain sensitive user data that should be masked, thus, a good regex for recognizing these columns would be snack_pref[0-9]+. A SNACK_PREF domain has been created with an appropriate algorithm for this type of data. To match the column name to profile, the type of classifier needed is PATH.
First, perform a GET operation on the classifiers/frameworks path. In the output below, the respective frameworkId of the PATH classifier is 3.
{
"_pageInfo": {
"numberOnPage": 4,
"total": 4
},
"responseList": [
{
"frameworkId": 1,
"frameworkName": "REGEX",
"description": "The regex framework can be used to specify one or more regular expressions to match the data in a field."
},
{
"frameworkId": 2,
"frameworkName": "LIST",
"description": "The list framework can be used to specify one or more value lists to match the data in a field."
},
{
"frameworkId": 3,
"frameworkName": "PATH",
"description": "The path framework can be used to specify exact values or regular expressions to match the name of a field."
},
{
"frameworkId": 4,
"frameworkName": "TYPE",
"description": "The type framework can be used to specify valid types and type lengths for fields to rule out invalid data types and lengths during classification."
}
]
}
After determining that classifier 1 has frameworkId=3, perform the GET operation on classifiers/1:
{
"classifierId": 1,
"classifierName": "Account Number - Path",
"frameworkId": 3,
"domainName": "ACCOUNT_NO",
"createdBy": "System",
"builtIn": true,
"classifierConfiguration": {
"paths": [
{
"matchType": "REGEX",
"fieldValue": "(?i)(?>(account|accnt|acct)_?-? ?(number|num|nbr|no|user))$",
"parentValue": "",
"caseSensitive": false,
"matchStrength": 0.67,
"allowPartialMatch": true
}
],
"rejectStrength": 0
}
}
To exemplify, this configuration is edited, replacing several configuration values to create a new classifier:
{
"classifierName": "Snack Preference - Path",
"frameworkId": 3,
"domainName": "SNACK_PREF",
"classifierConfiguration": {
"paths": [
{
"matchType": "REGEX",
"fieldValue": "snack_pref[0-9]+",
"parentValue": "",
"caseSensitive": false,
"matchStrength": 0.67,
"allowPartialMatch": false
}
],
"rejectStrength": 0
}
}
This body can then be used with a POST operation to the classifiers path to create the new classifier. The API response will include the newly assigned classifierId.
LIST type classifiers
Note that LIST type classifiers require one or more input files to define the value lists for recognition. These files must first be uploaded by doing a POST to the fileUpload API endpoint. The resulting fileReferenceId values may then be used for fields of type FILE in the classifier configuration when creating the classifier.
Configuration considerations for classifiers
Designing classifiers is significantly more complex than search or type expressions, as classifiers offer more flexibility in matching logic and configuration around match strength. Classifiers contain more configuration, typically encompassing all logic of the framework's type for a particular domain. For example, where a legacy profile set might have three different column level search expressions, these would all be consolidated into a single PATH type classifier. Classifiers also add the notion of rejection strength, allowing the profiling logic to eliminate domains from consideration earlier in the profiling process.
Strength values
Match and reject strength values in classifiers range from [-1.0, 1.0], which correspond to the [-100, 100] confidence values used in the UI, respectively. Currently, the product does not display confidence values for non-matches, so only values between [0, 100] are typically visible. The values -1.0 and 1.0 are treated as absolute rejection or confirmation, respectively; if a classifier returns -1.0, the domain in question may be immediately eliminated from the set of possible matches, meaning no other classifiers for that domain will be checked. Similarly, a 1.0 result will assign that domain matching without checking any other classifiers for that domain.
When multiple classifiers produce match or reject strength values, those results may be combined to get a final confidence. If the results conflict, with opposite signs, the result with the highest absolute value takes precedence. If the results have the same sign, the final result for that domain is a stronger match. The exact values and formula applied are under development and may change in the future. Currently, only the strongest column level result and strongest data level result are combined in this fashion.
Examples
-
A column named "ssn_present" matches a PATH classifier for the SSN domain with a match strength of 0.67. However, the column is boolean type and does not match the TYPE classifier for the SSN domain, which returns a -1.0 result. The verdict is -1.0 and the SSN domain is not assigned.
-
A column named "passport_no" contains 9 digit numeric values, which match the REGEX classifiers for both the SSN and PASSPORT_NO domains. Both REGEX classifiers return a confidence of 0.5 for this match. However, while the PATH classifier for the PASSPORT_NO domain matches and returns a match strength of 0.67, the PATH classifier for the SSN domain does not match, returning 0. The final confidence values are PASSPORT_NO at 0.84, and SSN at 0.5, so the PASSPORT_NO domain is the best match and the PASSPORT_NO domain and associated masking algorithm are assigned to the column.
Default assignment threshold
The default minimum confidence value that must be met for the ASDD profiler to assign a domain and algorithm is significantly different from the legacy profiler. By default, this value is 1, so any positive match, no matter how weak, will trigger an assignment. The legacy profiler by default requires an 80% match for data level expressions. This value is controlled by the application setting ASDD/DefaultAssignmentThreshold; refer to this section for details.
Choosing values for match strength
The value for match strength (typically matchStrength in the classifier configuration) reflects how confident the classifier is that a particular data element exclusively matches the associated domain. A match strength of 0.01 indicates that the data element may belong to the domain, but might also belong to any number of other domains or not be sensitive at all, while a value of 1.0 reflects absolute certainty that this data matches this domain and no other domain. A value of 0 provides no information. Not all classifiers have a greater than 0 match strength. One example of this is TYPE classifiers, which typically have a high reject strength, but 0 match strength (since it is impossible to match any of the built-in domains based on the data type of a column alone).
PATH classifiers built-in to product typically have a .67 match strength, so in order for a REGEX or LIST classifier to override a PATH result, that classifier's match strength or reject strength would have to be higher than this value. This can help eliminate false positive results from the PATH classifiers, but be wary of the next recommendation before setting match strength to a high value.
When choosing match strength for REGEX classifiers, consider whether the pattern is unique to the type of sensitive data being detected. If it is not, it is safer to give a relatively low match strength in the range of 0.1 to 0.5, so that PATH level results can contribute information. Consider this example of REGEX detection of US Social Security numbers. These might be stored as a string value with a more distinct pattern like "001-23-4567", or simply as a 9-digit number "001234567". A 9-digit number might be any number of other numeric identifiers, like account number, passport number, a row identifier for rows in another table, etc. so the match strength for the [0-9]{9} regex should be quite low. The distinct text pattern with dashes has a much higher match strength since it is unlikely to be any other kind of information.
Choosing values for reject strength
The reject strength (typically called rejectStrength in the classifier configuration) value reflects how likely it is that a value matches the classifier's domain when the classifier does not match. If you are certain that your classifier configurations will match every possible value for the domain, the reject strength should be set to 1.0; however, this degree of certainty is rare. Similar to match strength, not all classifiers provide any rejection capability. This is true of PATH classifiers, for example, as we cannot rely on an unknown database schema to use predictable or human-readable names for columns.
The reject strength for classifiers applies any time there is no match. For example, if a REGEX classifier contains 4 regular expressions, each expression would be tested against the column data value, and if none match, the reject strength defines the result. For this reason, it can be useful to add a pattern that matches quite broadly, even if it's not particularly selective for the domain in question, with a low match strength. This prevents a full rejection for values that might match this classifier's domain as well as one or more other domains.
For LIST and REGEX classifiers where the set of patterns or list values is known to be only a subset of possible values for the domain, reject strength should be below 0.5 to allow column level matches to take precedence, even if none of the data values match. For example, the value lists built-in for first and last name LIST classifier only contain English values, and names might be in other languages. These classifiers have "reject strength" set relatively low, to prevent the LIST classifiers from overriding the PATH classifier match if, for example, the column contains only Japanese names.
Regex configuration
The PATH and REGEX classifier types consume regular expressions using Java 8 regex syntax and matching logic. These classifiers have additional configuration options to control whether these patterns should match the entire input, and whether they are case-sensitive. For this reason, avoid using regex constructs such as "^(pattern)$" for these purposes.
Type classifiers
The TYPE classifier framework uses the same four types as Type Expressions, as described in the Managing expressions section. However, the type-matching system is more versatile and provides better type identification across all database variants.