
The Continuous Compliance Engine supports connecting to files and mainframe datasets stored in S3.
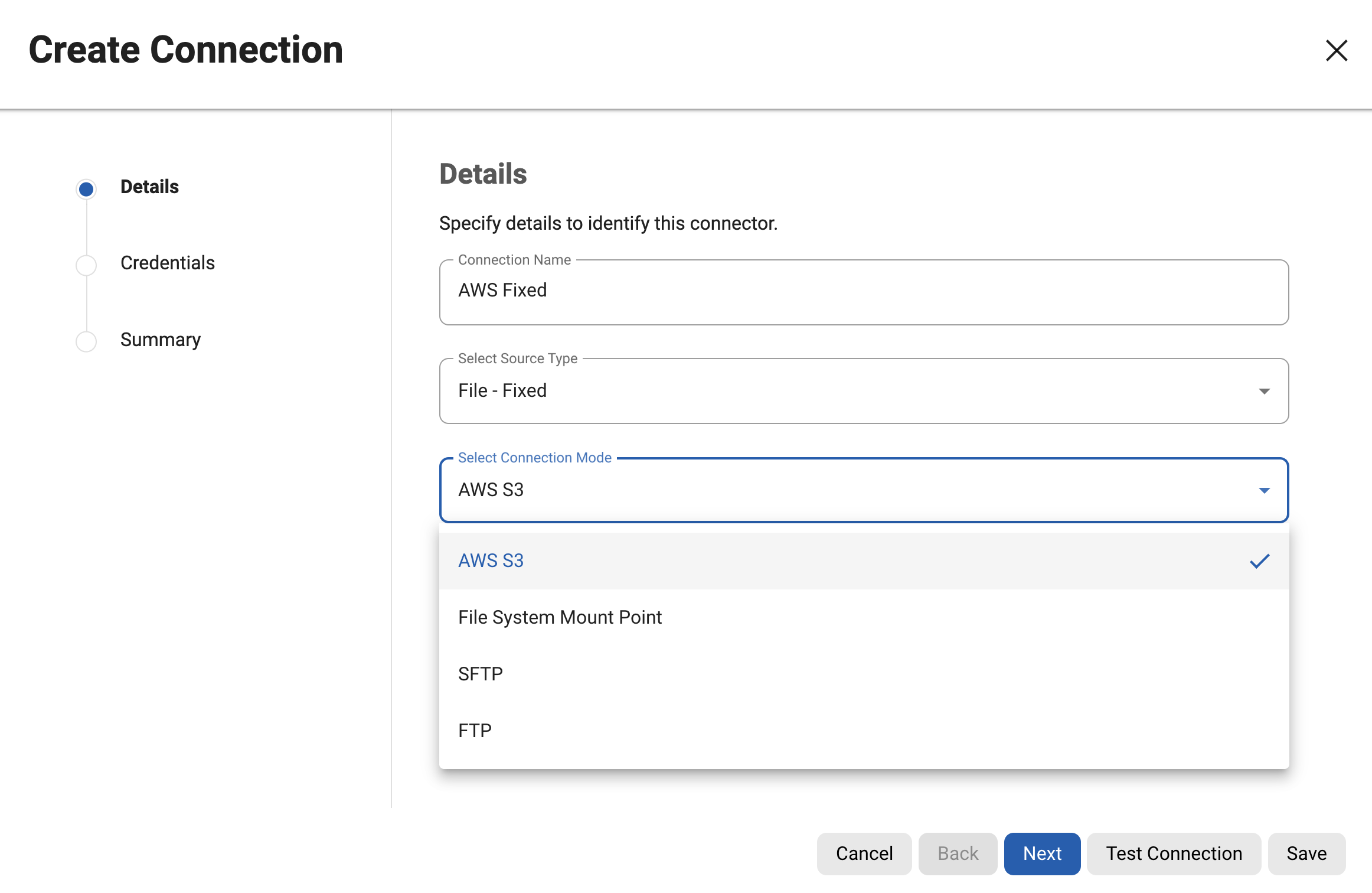
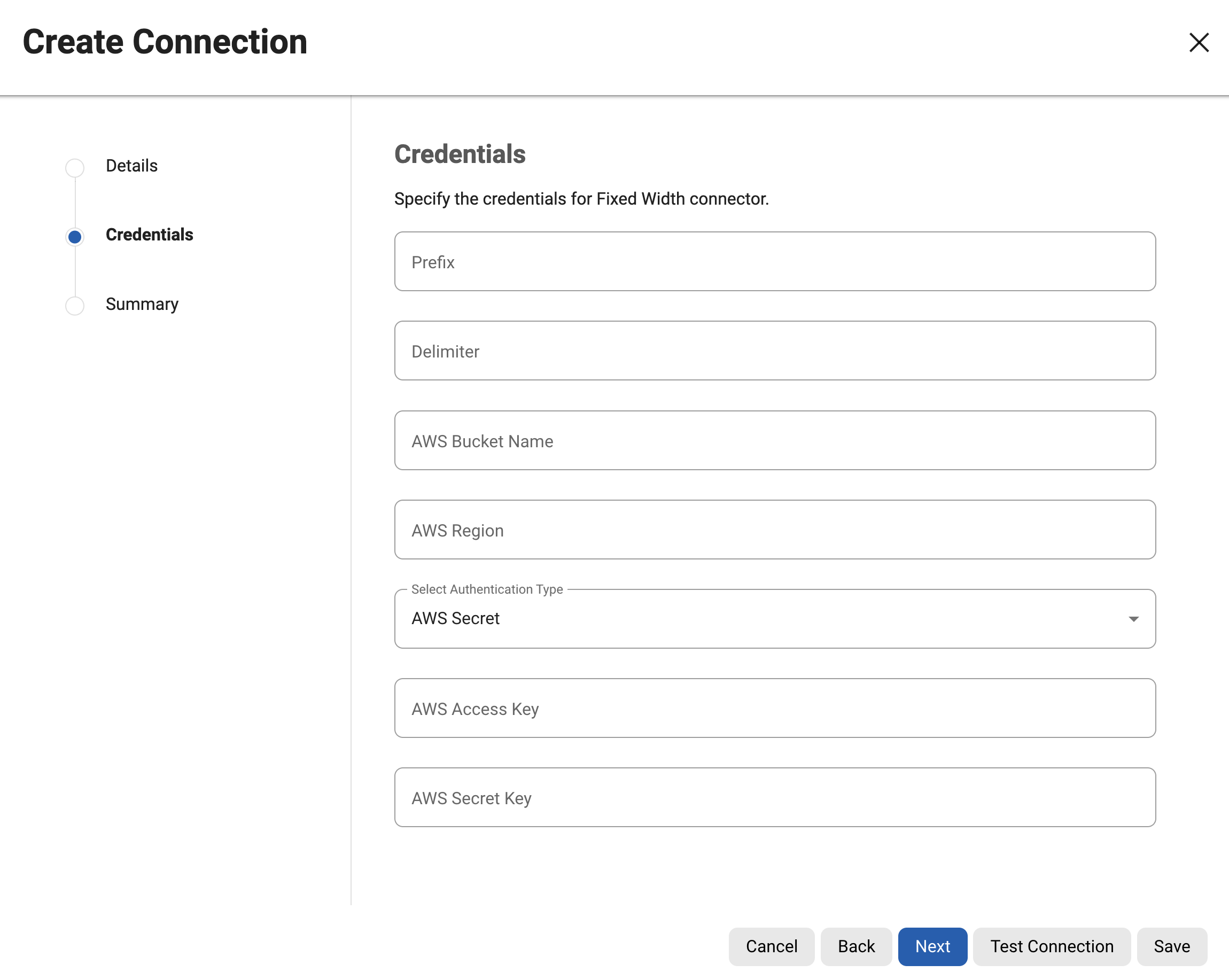
Configuring an S3 Connector
-
connectorName: Specifies the name of the connector.
-
environmentId: Indicates the identifier of the environment where the connector will be configured.
-
fileType: Denotes the type of files to be managed by the connector.
-
connectionInfo: This section contains details necessary for establishing a connection to the S3 service.
-
connectionMode: Specifies the mode of connection, which is set to "AWS_S3" indicating that it connects to an S3 bucket.
-
prefix: Indicates the prefix to be used for identifying files within the S3 bucket.
-
delimiter: Specifies the delimiter used in the file paths within the S3 bucket.
-
awsRegion: Specifies the AWS region where the S3 bucket is located.
-
awsBucketName: Specifies the name of the S3 bucket to connect to.
-
awsAuthType: The Continuous Compliance Engine offers support for connecting to S3 through two authentication methods: AWS secret-based authentication( AWS_SECRET ) and AWS Roles based authentication( AWS_ROLE ).
-
Secret-based authentication requires:
-
awsAccessKey: The access key is a Alphanumeric string that uniquely identifies your AWS account.
-
awsSecretKey: The secret key is associated with your access key and is used for signing requests to AWS services.
For more information related to prefix and delimiter, please refer to the Amazon Simple Storage Service documentation.
Sample payloads
-
AWS Secret
To connect to S3, Continuous Compliance requires a user's AWS Access Key and Secret Key for authentication.
{
"connectorName":"JSON S3",
"environmentId":37,
"fileType":"JSON",
"connectionInfo":{
"connectionMode":"AWS_S3",
"prefix":"json/",
"delimiter":"/",
"awsRegion":"us-west-2",
"awsBucketName":"masking-bucket-name",
"awsAuthType":"AWS_SECRET",
"awsAccessKey":"<Your AWS Access Key>",
"awsSecretKey":"<Your AWS Secret Key>"
}
}
-
AWS Role
To establish secure communication between a masking engine hosted on EC2 instance and S3, we leverage instance profiles. This approach eliminates the need for static access keys and enhances security by dynamically providing temporary credentials.
{
"connectorName":"JSON S3",
"environmentId":37,
"fileType":"JSON",
"connectionInfo":{
"connectionMode":"AWS_S3",
"prefix":"json/",
"delimiter":"/",
"awsRegion":"us-west-2",
"awsBucketName":"masking-bucket-name",
"awsAuthType":"AWS_ROLE"
}
}
S3 upload sizing
S3 supports object sizes up to 5 TB. When uploading objects larger than 100 MB, Amazon recommends using a multipart upload. As the name implies, a multipart upload breaks the object into smaller parts where each is assigned a part number. S3 supports breaking an object into at most 10,000 parts.
When uploading a masked object, Continuous Compliance uses a multipart upload. The part size is calculated by multiplying 20% times the masking job’s maximum memory and then dividing by the masking job’s number of streams. For example if maximum memory is 2 GB and the number of streams is 1, then the part size would be (20% * 2 GB) / 1 = 400 MB.
When working with a large object, you must configure the masking job’s maximum memory and streams so that the object can be uploaded in at most 10,000 parts. For example if you need to mask a 5 TB object (the maximum size for an S3 object), then the part size must be greater than or equal to 5 TB / 10,000 parts ≅ 525 MB. If you plan to use 1 stream, then the maximum memory should be (1 * 525 MB) / .2 = 2,625 MB or more.
For more information related to multipart uploads, please refer to: