
Secure Lookup is the most commonly used type of algorithm. It is easy to generate and works with different languages. When this algorithm replaces real, sensitive data with fictional data, it is possible that it will create repeating data patterns, known as “collisions.” For example, the names “Tom” and “Peter” could both be masked as “Matt”. Because names and addresses naturally recur in real data, this mimics an actual data set. However, if you want the Masking Engine to mask all data into unique outputs, you should use Character Mapping.
Starting in version 6.0.4.0, we introduced a built in Extensible Secure Lookup Algorithm Framework. The new framework uses SHA256 hashing method and allows case configurations for input and output (i.e. masked) values.
Creating a secure lookup algorithm via UI
-
At the top right of the Algorithms page, click + Algorithm.
-
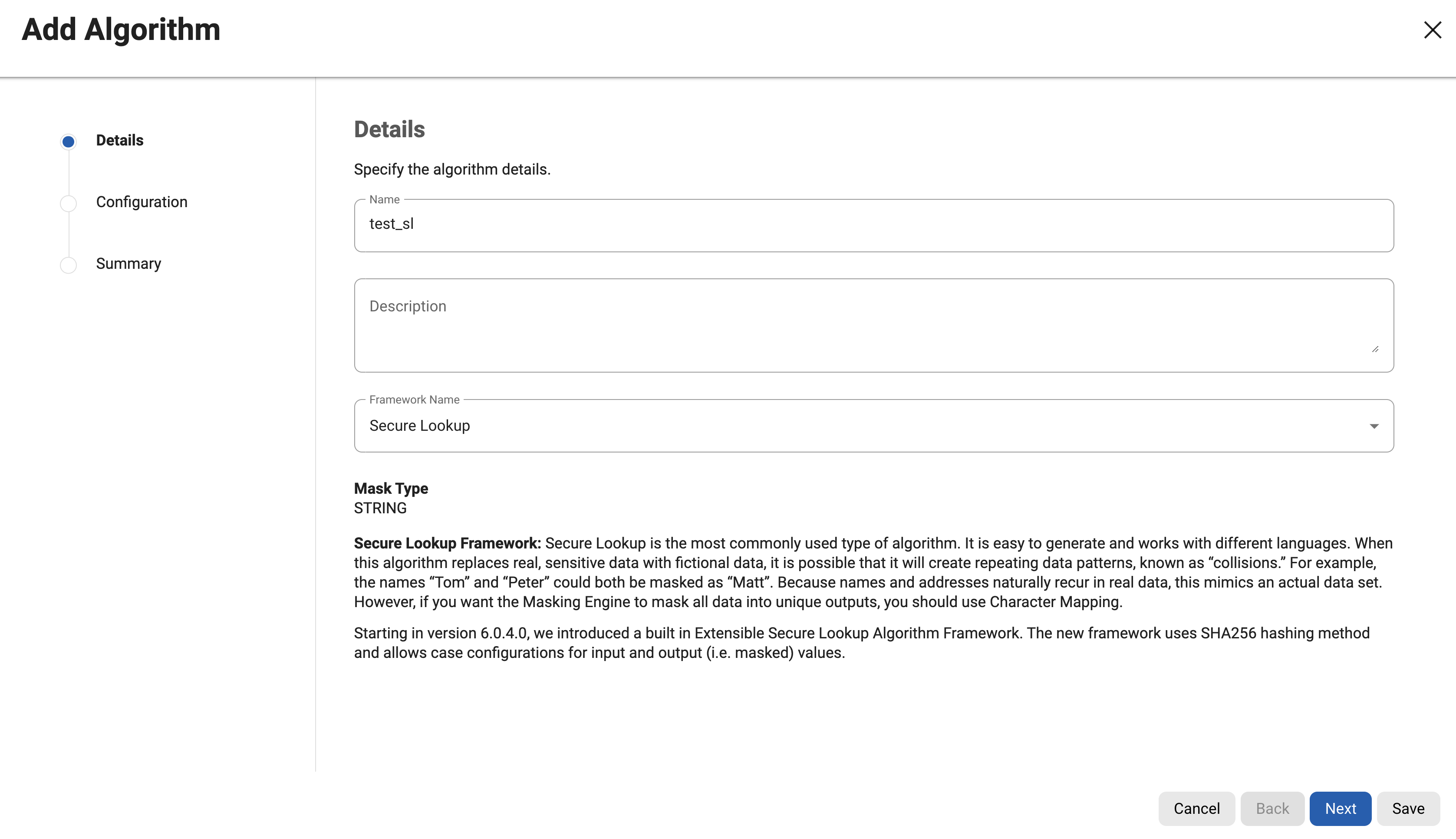
Enter an Algorithm Name.
Info: This MUST be unique.
-
Enter a Description.
-
Select Secure Lookup as the Framework Name and click Next.
-
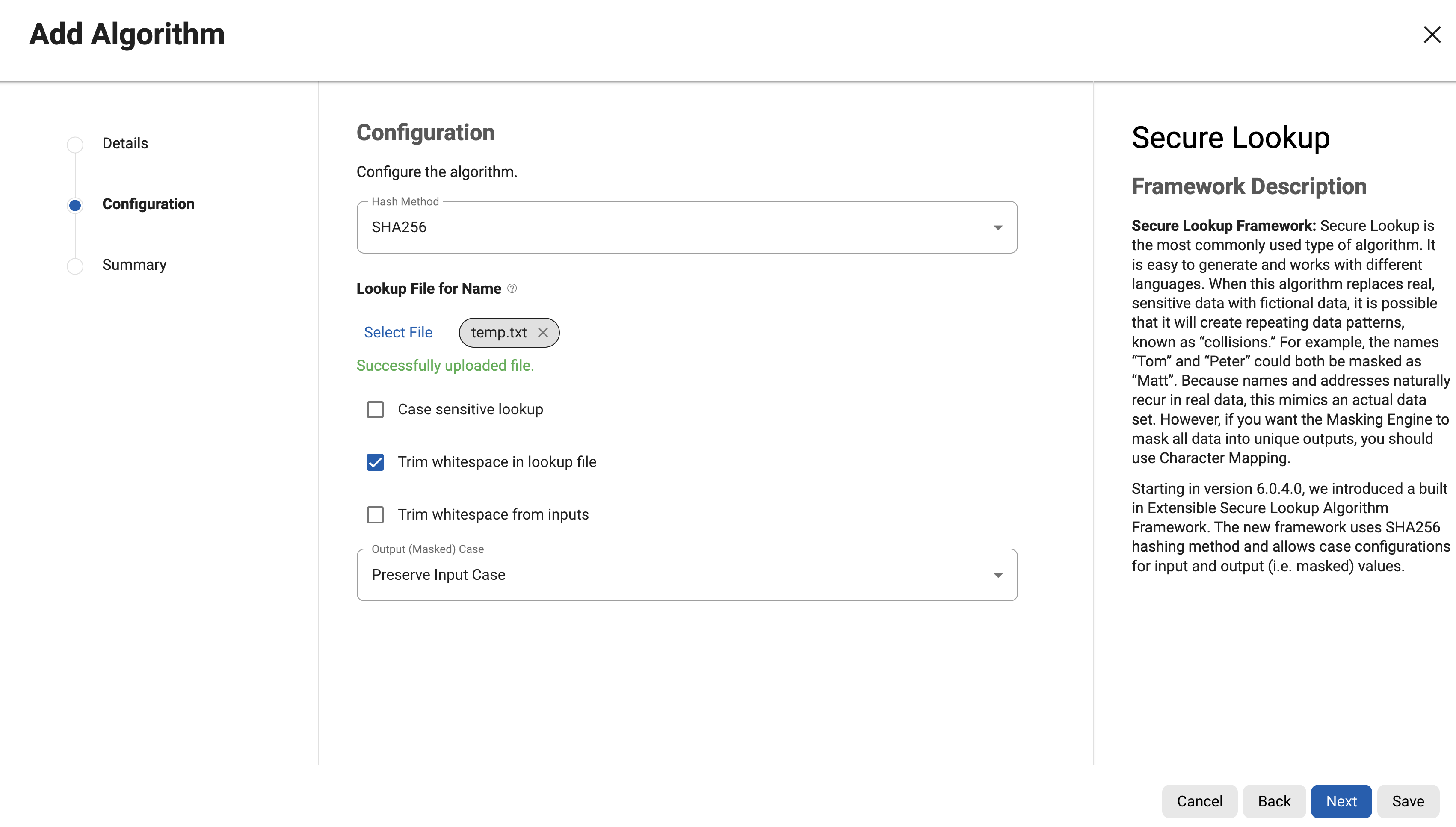
Choose the Hash Method configuration for lookup determination.
-
SHA256 - This hash method is the default hash method for extensible secure lookup algorithms.
-
LEGACY - This hash method is used to mimic the legacy secure lookup behavior in the extensibility framework.
-
RANDOMIZE - This method replaces the input value with a random value from the lookup file. It internally uses a PRNG (pseudorandom number generator) to generate a random index with a uniform distribution (equal probability) which is subsequently used to fetch the value from the lookup file.
-
-
Specify a Lookup File. This file is a single list of values that does not require a header, every line of the Lookup File might be used as a masked value. The Lookup File must be ASCII or UTF-8 encoding compatible. The lookup file can be referenced locally or with a specified/uploaded URI. The following is sample file content:
Smallville Clarkville Farmville Townville Cityname Citytown Towneaster -
Choose the Case Sensitive Lookup configuration. If the Case Sensitive Lookup box is marked then the same input of different cases will be masked to the different values. For example:
Peter -> John peter -> AndrewIf that setting is not marked (which is a default option), then the lookup would be case insensitive, for example:
Peter -> John peter -> John -
Choose the Trim whitespace selections.
-
Choose the Output (Masked) Case configuration.
-
Preseve Lookup File Case - keep the masked value as found in the Lookup File.
-
Preserve Input Case - check the input case, which can be one of the following three:
-
All uppercase - in that case, force the whole masked value to uppercase.
-
All lowercase - in that case, force the whole marked value to lowercase.
-
Mixed (if at least 1 character case is different from others) - in that case keep the masked value as found in the Lookup File
-
-
Force all Uppercase - forces the whole masked value to uppercase
-
Force all Lowercase - forces the whole masked value to lowercase
-
-
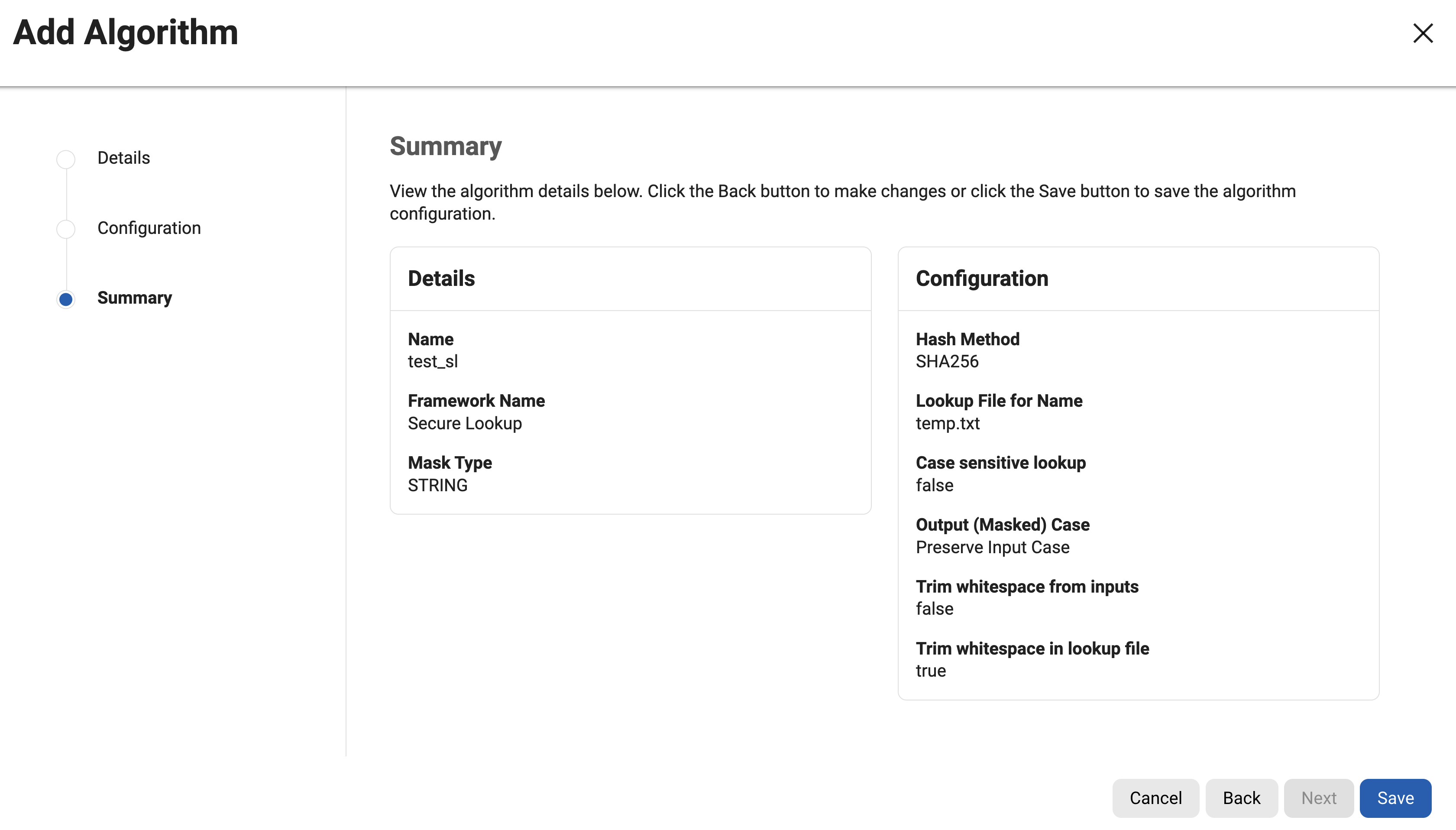
Click Next to verify details on the Summary step.
-
When you are finished, click Save.
-
Since the RANDOMIZE hash method chooses a random replacement value every time, this does not maintain referential integrity and should never be used in cases where referential integrity is required. This is however useful in certain cases where masked values need to reflect a statistical distribution (ex: genders, model a population distribution, etc.)
-
Before using the algorithm in a profiling job, you must add it to a domain.
For information on creating Secure Lookup algorithms through the API, see API Calls for Creating Algorithms - Secure Lookup.