
Introduction
This feature offers standard functionalities for masking JSON files. Users will now be able to configure and run Continuous Compliance jobs specific to JSON files, assigning algorithms to any field of a JSON file using their respective JSON paths. This feature overcomes shortfalls of the existing algorithm-based workaround by providing users with a simplified way to assign Continuous Compliance algorithms. This feature also supports masking JSON files of large sizes.
Profiling jobs for JSON file rulesets are not yet supported.
API changes
|
API |
Change Description |
|---|---|
|
|
Added support to upload a Json file to create JSON File Format. |
|
|
Added validations to stop creating headers and footers for JSON File Formats. |
|
|
Added support to create a new file connector of type |
|
|
Added support to create a new JSON File field, specifying its JSON path identifier and assigning algorithms to it. |
|
|
Added support to update JSON File field to assign or unassign algorithms to it. |
GUI changes
In the Continuous Compliance interface, navigate to Settings > File Format. Import the .json file to create JSON File Formats. Use the file you want to mask as the format.
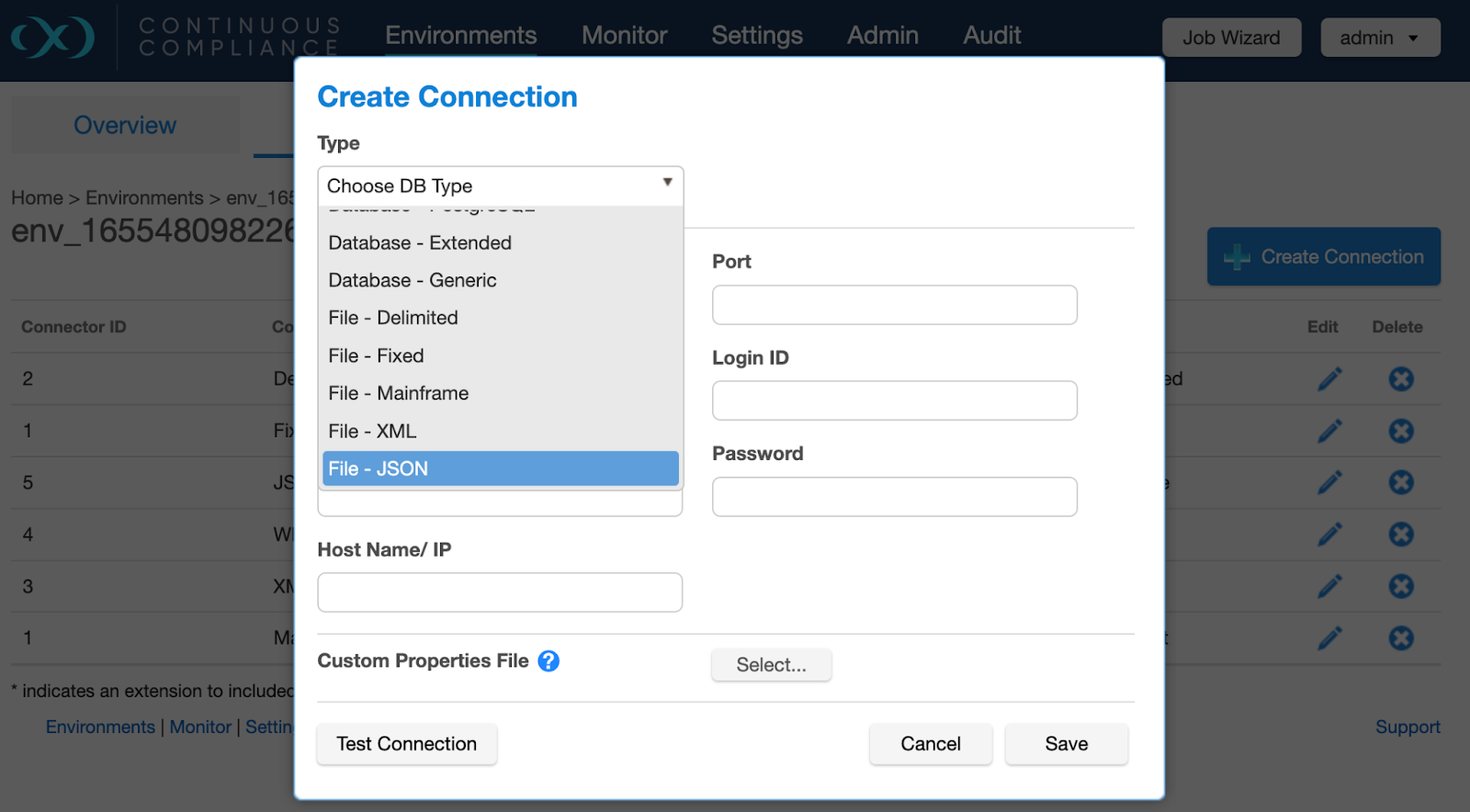
In the Create Connection screen, choose File - JSON from the Type dropdown and configure the appropriate details.
Below is an example of a JSON file:

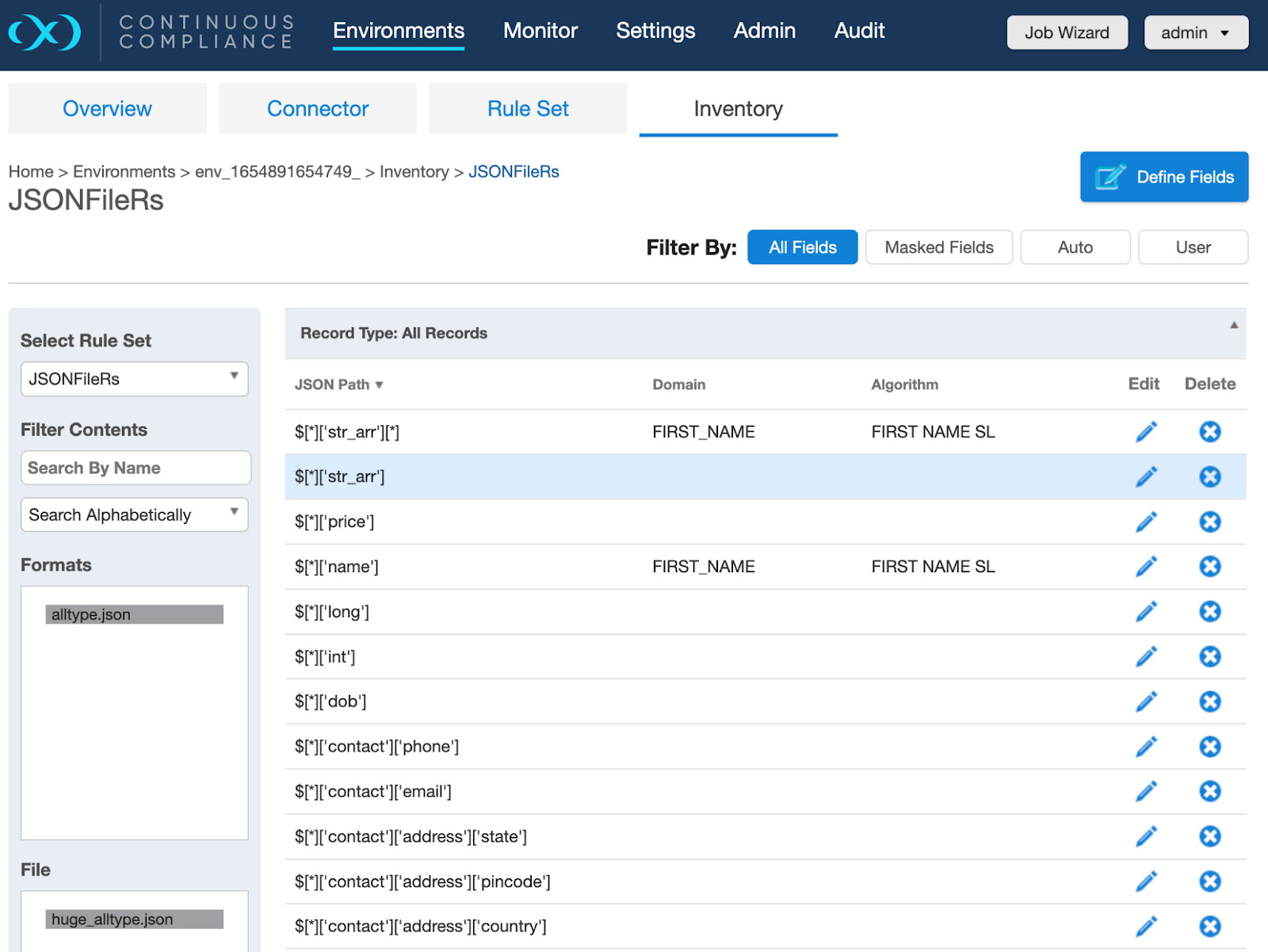
The Inventory tab for JSON file formats is used to configure algorithms to JSON paths and to add new JSON paths using the Define Fields button.
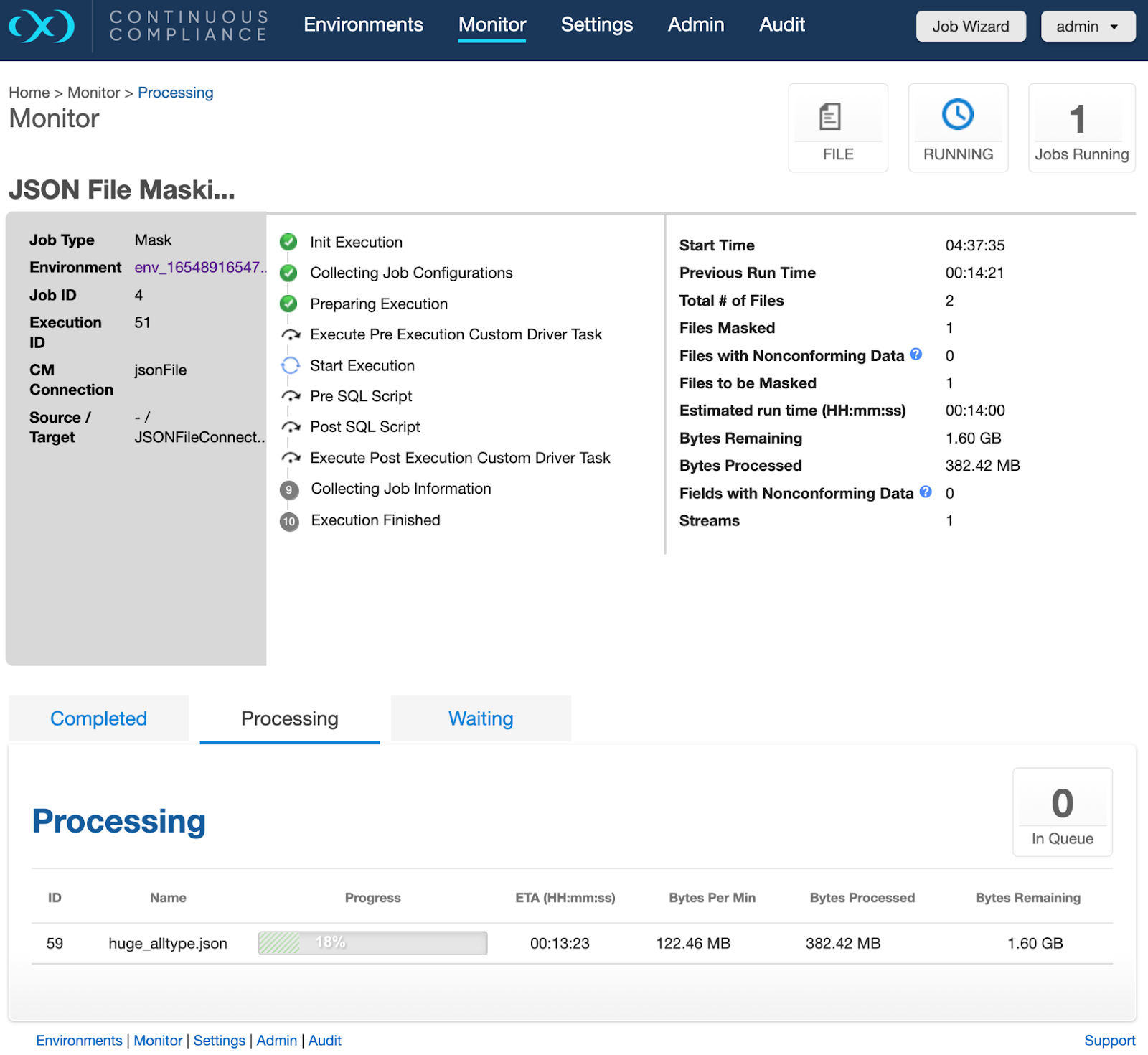
Navigate to Monitor > Processing to access the Job Process Monitoring page. This page shows data in byte format for JSON file masking.
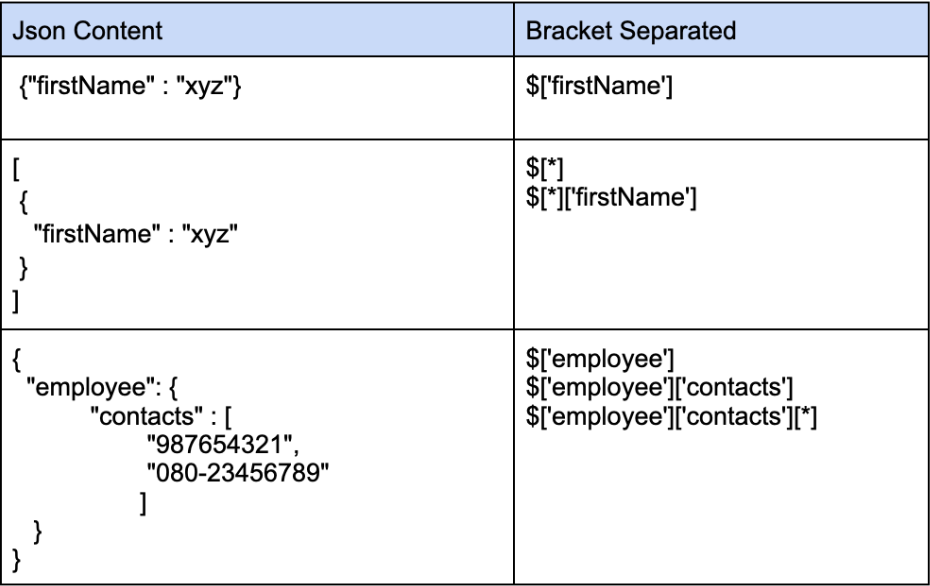
Constructing a JSON file path
A JsonPath expression begins with the dollar sign ($) character, which refers to the root element. The dollar sign is followed by a sequence of child elements, which are separated by the square brackets ([‘’]) containing the name of each JSON field. If the field is inside an array, a star character is used to represent all elements of the array ([*]).
Multi-column algorithm support
Starting with version 10.0.0.0, JSON file masking with limited buffer-data size will support multi-column algorithms. This enables the use of multiple algorithms to mask data in JSON files, even if the file is large.
Buffer size (in bytes) will be calculated using the formula below:
((Max_memory_of_Job/No_of_streams_for_job)*CharStreamingBufferLimitRate)/100
-
The default values will be used when the maximum memory and number of the stream for the job are not defined.
-
Buffer-data size is configurable via the application setting
CharStreamingBufferLimitRate, under Mask group settings. To adjustCharStreamingBufferLimitRate, refer to Masking API Client.
The fields with multi-column assignments should not exceed the limit of buffer data size. In a case of exceeding the limit of buffer data size, the job will fail. Users can configure buffer size by adjusting CharStreamingBufferLimitRate to avoid exceeding the buffer data size limit issue.
-
Multi-column algorithm is supported for JSON file and JSON Document store type masking.
-
Multi-column algorithm is not supported for JSON fields where,
-
JSON field is an array.
-
JSON fields are part of different arrays.
-
JSON fields are on different levels having one or more fields from JSON arrays.
-
Multi-column algorithm assignment for JSON fields will be validated at the time of assignment. If any of the above combinations are found while assigning a multi-column algorithm, that assignment will not be allowed.
Below is a sample JSON file format with valid and invalid multi-column assignment examples.
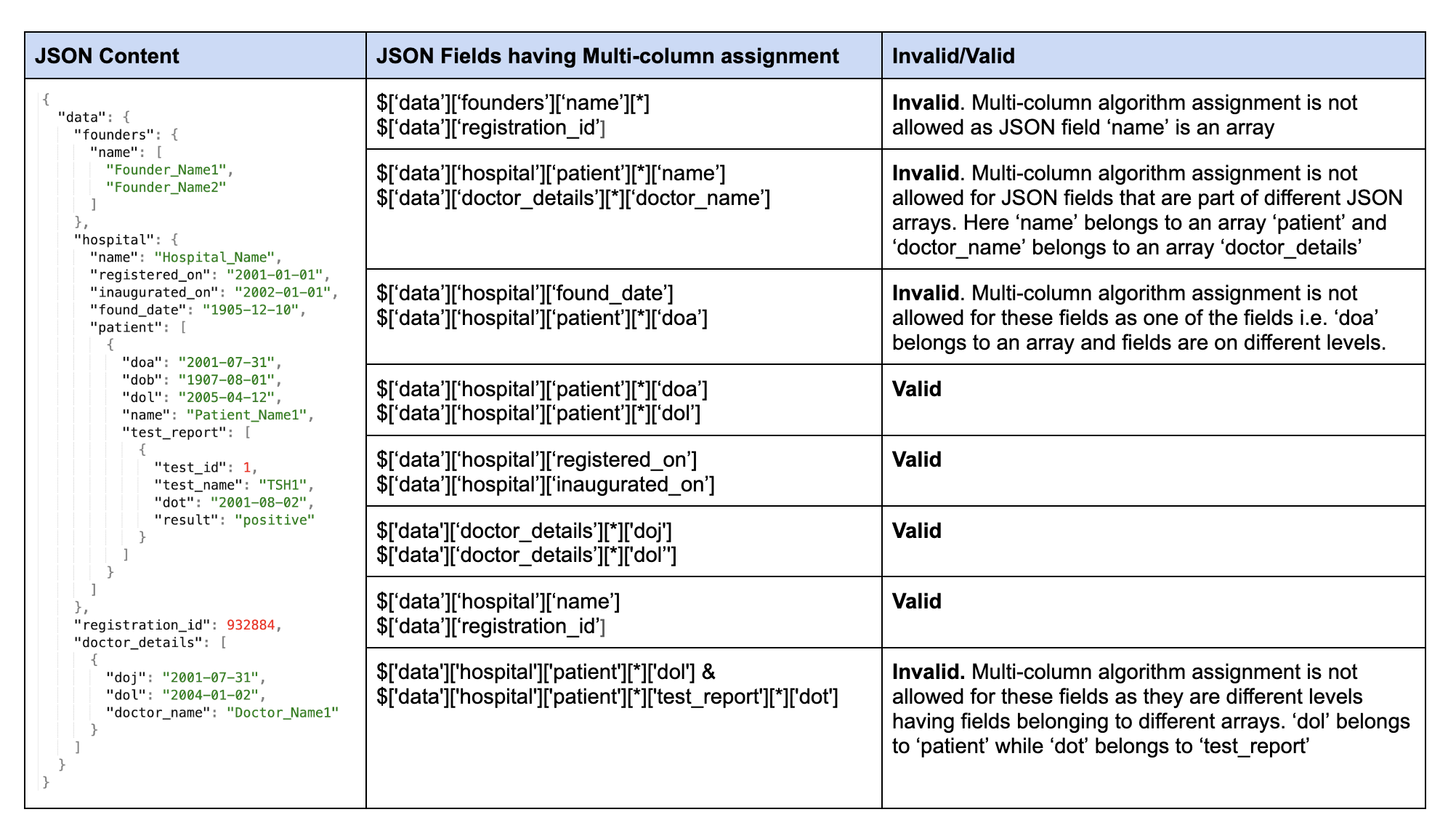
Assigning a multi-column algorithm to an invalid combination of JSON fields will produce an error that shows JSON paths.
